
Table of Contents
Introduction to Agent-R1
Agent-R1 is a next-generation autonomous agent framework that is gaining attention in artificial intelligence research for its ability to extend and redefine traditional decision-making models. Unlike conventional reinforcement learning systems, Agent-R1 is designed to handle uncertainty, long-term planning, and partial observability in real-world environments. The growing interest in Agent-R1 reflects a broader shift toward AI agents that can reason, adapt, and learn continuously rather than operate within rigid, predefined rules. By reimagining how the Markov Decision Process functions in dynamic environments, Agent-R1 introduces a more realistic and scalable approach to autonomous intelligence.
Agent-R1 and the Evolution of the Markov Decision Process
The theoretical foundation of Agent-R1 is rooted in the Markov Decision Process, which has historically modeled agent behavior through states, actions, rewards, and transitions. Agent-R1 builds upon this foundation by expanding the definition of “state” beyond a single moment in time. In Agent-R1, states incorporate historical context, probabilistic beliefs, and environmental uncertainty, enabling more informed decision-making. This evolution allows Agent-R1 to operate effectively in environments where classical MDP assumptions break down, such as real-world robotics, financial systems, and complex simulations.
What Makes Agent-R1 a New Class of Autonomous Agent
Agent-R1 stands apart from traditional AI agents because it integrates perception, memory, and planning into a unified loop. While older agents rely heavily on immediate observations, Agent-R1 maintains an internal understanding of past experiences and future expectations. This internal modeling allows Agent-R1 to adapt when conditions change unexpectedly. The design philosophy behind Agent-R1 focuses on flexibility and resilience, making it suitable for environments that are non-stationary, partially observable, or adversarial in nature.
Core Architecture Behind Agent-R1
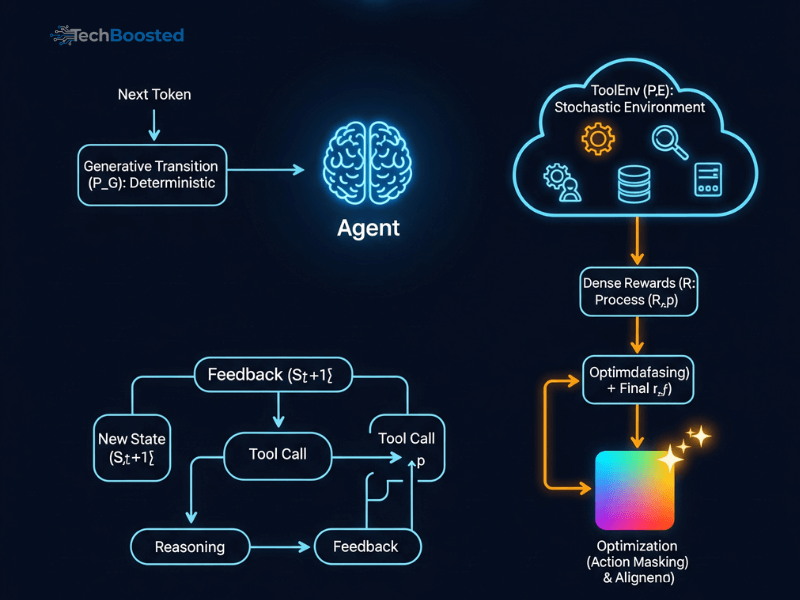
The architecture of Agent-R1 consists of four primary components: perception, world modeling, policy learning, and adaptive memory. The perception layer processes raw inputs such as sensor data, images, or text. The world model predicts future outcomes based on learned dynamics, while the policy layer selects actions that maximize long-term value. Adaptive memory is a defining feature of Agent-R1, allowing the agent to recall relevant experiences and apply them to new situations. This architecture enables Agent-R1 to behave intelligently over extended time horizons.
State Representation and Memory in Agent-R1
A key innovation of Agent-R1 lies in how it represents state information. Instead of relying on isolated snapshots, Agent-R1 constructs belief-based state representations that evolve over time. These representations combine current observations with stored contextual memory, enabling Agent-R1 to reason under uncertainty. This approach allows Agent-R1 to anticipate future outcomes, recognize patterns, and respond more effectively to rare or unexpected events.
Learning and Optimization Strategies Used by Agent-R1
Agent-R1 employs advanced learning techniques that blend reinforcement learning with model-based optimization and self-supervised learning. Rewards are not limited to external signals; Agent-R1 also uses intrinsic motivation such as uncertainty reduction and exploration efficiency. These strategies help Agent-R1 overcome challenges like sparse rewards and delayed feedback. As a result, Agent-R1 often learns faster and generalizes better than classical reinforcement learning agents.
Agent-R1 and Long-Term Decision Making
Long-horizon planning is one of the strongest advantages of Agent-R1. By using hierarchical decision structures, Agent-R1 can decompose complex goals into manageable sub-tasks. This allows the agent to align short-term actions with long-term objectives. In environments where decisions have delayed consequences, Agent-R1 demonstrates greater stability and strategic depth compared to conventional agents.
Practical Applications of Agent-R1 in Robotics
In robotics, Agent-R1 enables machines to operate autonomously in unpredictable environments. Robots using Agent-R1 can adapt to changing terrain, interact safely with humans, and learn from operational feedback. The memory-driven decision model of Agent-R1 allows robotic systems to improve over time, making it suitable for healthcare robotics, logistics automation, and industrial manufacturing.
Agent-R1 in Software-Based Autonomous Systems
Beyond physical robots, Agent-R1 is highly applicable to software agents such as digital assistants, automated research tools, and intelligent workflow systems. Agent-R1 allows these systems to maintain contextual awareness across long interactions, resulting in more coherent responses and improved task execution. This makes Agent-R1 a strong foundation for advanced AI assistants and enterprise automation platforms.
Safety, Alignment, and Reliability in Agent-R1
As Agent-R1 systems become more autonomous, safety and alignment are critical considerations. Agent-R1 frameworks often incorporate constraints, reward shaping, and human feedback to ensure alignment with user goals and ethical guidelines. Interpretability tools are also used to analyze how Agent-R1 arrives at decisions, improving transparency and trust in high-risk applications.
Comparison Between Agent-R1 and Traditional Reinforcement Learning
Compared to standard reinforcement learning agents, Agent-R1 offers superior adaptability and robustness. Traditional agents struggle with delayed rewards and hidden variables, while Agent-R1 leverages memory and predictive modeling to overcome these limitations. Although Agent-R1 may require more computational resources, the trade-off is improved reliability and performance in complex environments.
Challenges and Research Limitations of Agent-R1
Despite its promise, Agent-R1 faces challenges related to scalability, computational cost, and training complexity. Researchers continue to explore ways to optimize Agent-R1 for real-world deployment while maintaining interpretability and safety. Multi-agent coordination and transfer learning remain open research areas within the Agent-R1 ecosystem.
The Future Direction of Agent-R1 Development
Agent-R1 represents a significant step toward more general and adaptive artificial intelligence. As research progresses, improvements in efficiency, hardware acceleration, and integration with foundation models are expected. The continued evolution of Agent-R1 could play a crucial role in shaping the future of autonomous systems across multiple industries.
Conclusion
Agent-R1 is redefining how autonomous agents are designed by extending the traditional Markov Decision Process to handle real-world complexity. Through adaptive memory, richer state representations, and long-term planning, Agent-R1 addresses many limitations of classical reinforcement learning. As AI systems continue to evolve, Agent-R1 stands out as a foundational framework for building reliable, context-aware autonomous intelligence.
Frequently Asked Questions (FAQs)
What is Agent-R1?
Agent-R1 is an advanced autonomous agent framework that extends reinforcement learning with memory and long-term reasoning.
How does Agent-R1 improve decision-making?
Agent-R1 uses contextual state modeling and adaptive memory to make better decisions under uncertainty.
Is Agent-R1 suitable for real-world environments?
Yes, Agent-R1 is designed for dynamic and partially observable environments.
Does Agent-R1 replace traditional MDPs?
No, Agent-R1 builds upon MDPs while extending them for greater realism.
What industries can benefit from Agent-R1?
Robotics, automation, finance, healthcare, and intelligent software systems.
Is Agent-R1 still under research?
Yes, Agent-R1 is actively evolving with ongoing academic and industry research.
Stay connected with techboosted.co.uk for expert insights, in-depth explainers, and the latest updates on autonomous intelligence platforms and emerging AI technologies.